



Editor’s Note: In this article, “TAR” is used to describe “traditional technology-assisted review” (e.g. first Relativity Assisted Review and, as the technology evolved, active learning), while “generative AI” is being used to describe a generative-AI-based review (e.g. Relativity aiR for Review).
As generative AI has come bursting onto the legal scene over the last few years, many voices have rung out on social media, at conferences, and in meeting rooms to advocate for the technology and educate others on its benefits, limitations, and use cases. Some of those voices are focused on data science; others on legal ramifications.
Benjamin Sexton, vice president of e-discovery at JND Legal Administration, has been a particularly insightful voice during this time. His approachable yet expertly written insights on the use of AI for legal teams in general—and e-discovery practitioners specifically—have enabled many to embrace generative AI and have their questions about it answered.
This influential knowledge sharing is, without doubt, one of the reasons Ben earned the 2024 Relativity Innovation Award for Artificial Intelligence. To celebrate his win and learn more about his experience with AI for e-discovery, we sat down with Ben for the following interview. Read on for his delightful anecdotes and expert lessons on AI.
Sam Bock: Tell us a little about your career in e-discovery. How did you land in this field?
Ben Sexton: In 2008, I graduated from the University of Minnesota with a degree in mathematics and no idea how to connect that with a paycheck. I was working part time at the university on a Fermilab experiment called the NOvA project, prototyping components for a 14,000-ton neutrino detector. The goal was to transmit neutrinos for the Fermilab particle accelerator (which is not far from Relativity’s HQ) to a detector located in the Soudan Underground Mine in Northern Minnesota.
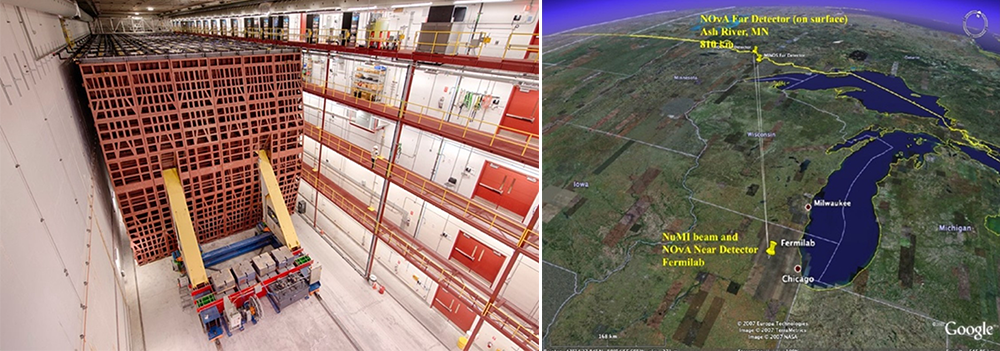
At one point we needed to ship several tons of large but sensitive components to the mine site. The catch was that the cargo could easily be damaged if jarred. The solution: We taped iPhones (which had just come out in 2007) to each container and used the accelerometer data to monitor G-forces for any shocks. I really enjoy that kind of hands-on, improvisational problem solving.

But, alas, 2008 struck. To make ends meet, I worked mornings at Home Depot and valeted cars at night. A fellow valet, Sam Savage (who went on to found Savage Westrick PLLP), set me up with an interview with a local litigation boutique named Paperchase Litigation Technology, where he was managing scanning projects. I recall the logo on the door looked like a hotdog.
It wasn’t particle physics, but there were plenty of puzzles to solve. I was improvising, bootstrapping, and fixing things that made a difference for real people. The puzzles got bigger and more challenging, and I’ve been hooked ever since.
What was your first exposure to AI? When did you start using TAR?
I first used TAR in 2012 in a large antitrust MDL. We were on the plaintiff’s side, and, to date, the case received more than 300 productions via CDs and DVDs—half of which were Summation dii files—totaling a few million documents. The client asked if there was any way to use technology to “speed up” the review.
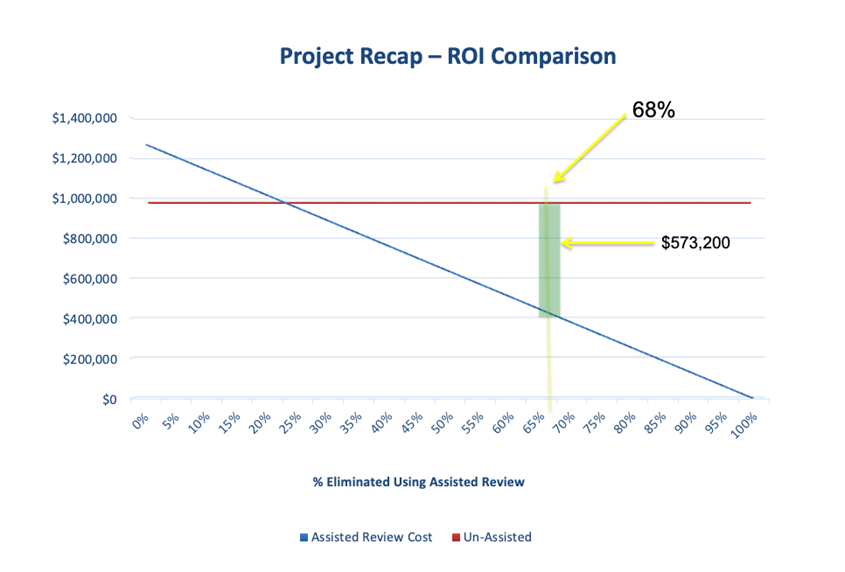
It had been less than 12 months since Judge Peck’s ruling in Da Silva Moore, approving the use of TAR, and we’d seen promising results from Relativity Assisted Review on a few smaller projects. We made the pitch, and the client was receptive to everything but the price. Fortunately, almost anything has better ROI than eyes-on review, so we did some modeling and were able to overcome the price tag. While the early days of Assisted Review were not pretty compared to active learning today, the project was ultimately a success. We were able to demonstrate ROI over eyes-on review, noted in this slide from the project wrap-up meeting.
I can’t talk about early TAR without mentioning a CLE I did in 2014 in Sturgis, South Dakota. The topic was the “ROI of TAR.” Picture a room of attorneys and judges dressed in chaps and cuts, listening to me talk about LSI.

Truth is, it was a great conversation. We had a hearty discussion with lots of good questions. The post-conference ride didn’t go quite so well, though. We got caught in a rain storm, and I wound up breaking the starter on someone’s vintage Honda Superhawk.
What was adoption like for TAR when you initially started offering it to clients?
Despite its well-established benefits, TAR did not sell like wildfire. The idea of not laying eyes on every document took some getting used to. TAR felt like a black box, and every aspect of the machine learning conversation was brand new for most lawyers. I sympathize to an extent. I remember once being asked by a partner, “How much money will TAR save us?”—and watching the life drain from his face as I used more than one word to answer.
The high price tag was no help and made the ROI less obvious. A 2013 paper, “Predictive Coding Primer Part One: Estimating Cost Savings,” documented then-current rates at $300–$700 per gigabyte.
Fortunately, over the last 12 years, we’ve seen the landscape for adoption improve considerably. The cost of TAR has dropped to free (or nearly free), and lawyers are more tech-savvy than they were in 2012. All the while, document populations continued to grow, and we have, by necessity, grown accustomed to the idea that it isn’t feasible to review every document.
Maybe surprisingly, since generative AI has hit the scene, we’ve actually seen the biggest spike in TAR utilization in the last 10 years. With a new “bleeding edge,” I think TAR is feeling less controversial. There are a lot of internal directives to cut costs using AI, and for some, TAR has felt like the “safer” answer.
What is adoption like for Relativity aiR? Do you find it easier to use, or faster, than TAR? What are some common challenges with generative AI?
We’ve seen an accelerated adoption curve for aiR. The number one reason is that lawyers are more educated on technology in 2024 than they were 10+ years ago. Statistical validation is “court-approved” and even required by many ESI protocols. The lens today is less focused on “what’s in the black box?” (process) and more on “did it work?” (results). We have TAR to thank for doing a lot of the heavy lifting.
I also think aiR is simply more intuitive to lawyers than traditional TAR. aiR provides rationales, considerations, and citations to explain its decisions. If you disagree with a determination, you simply update the prompt with more context, or additional instructions, and you immediately see the impact on the results.
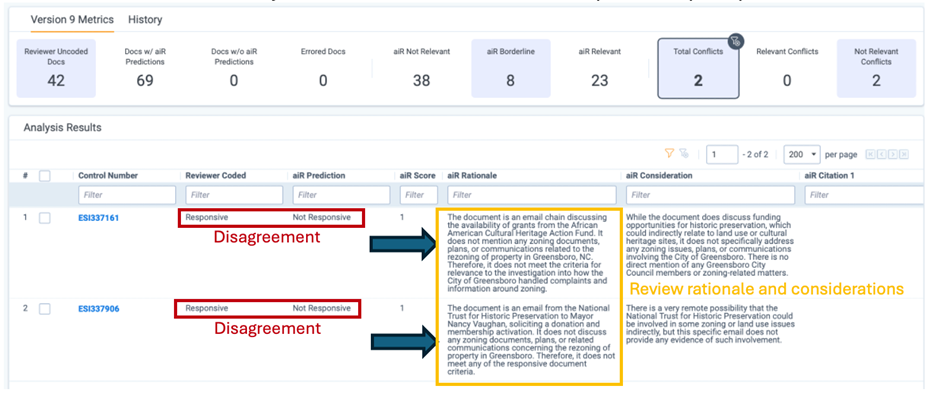
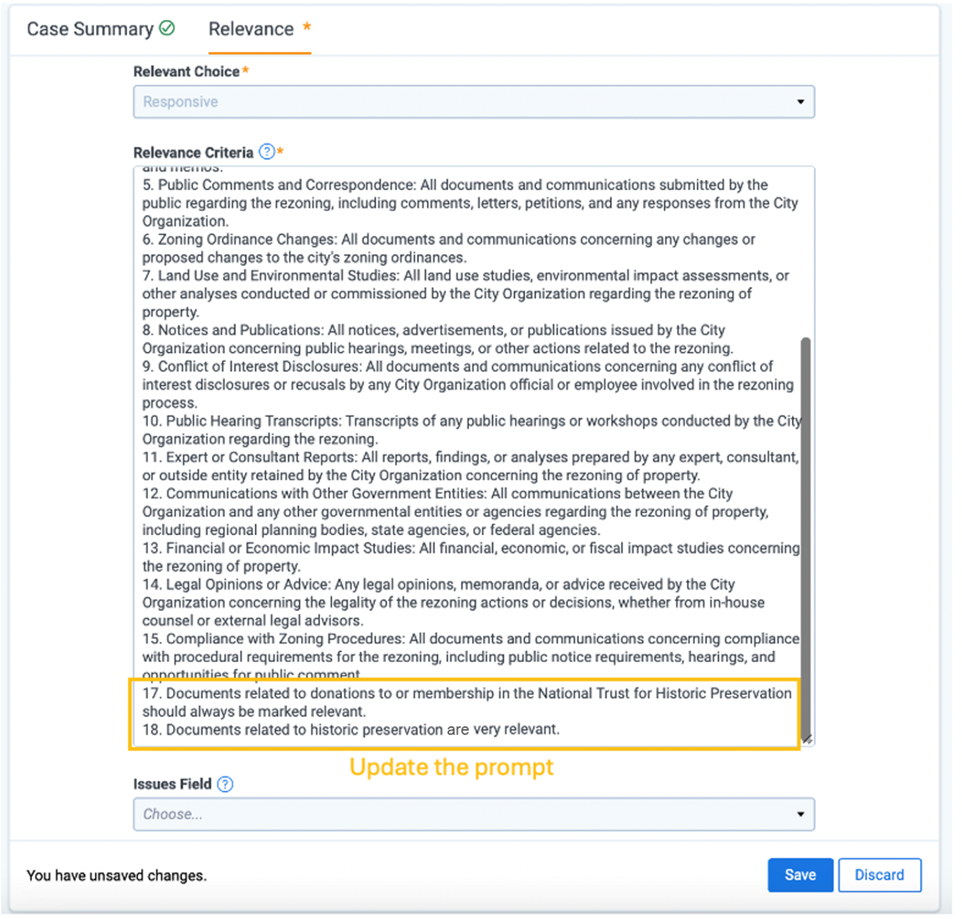
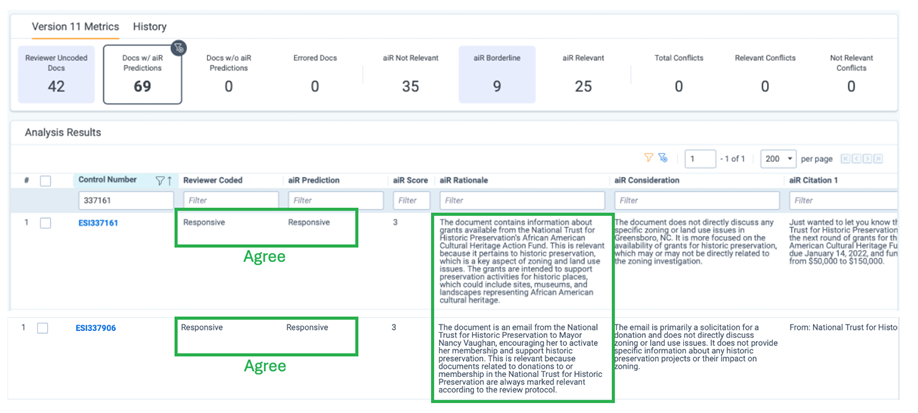
The traceability and flexibility to maneuver finer details with written language is compelling.
In a nutshell, we have a legal pathway for adoption carved by TAR, and a technology that people like to use, which is a recipe for adoption.
How many jobs have you now run in aiR?
Right now, we’re about a year into using aiR and have run around 460 aiR for Review jobs. We should cross the million-document mark in the next few weeks. It’s been a lot of fun for me and Rachel Koy, and we’ve learned a ton.
Do you still use TAR on some cases? How do you consult clients on whether to use TAR or aiR for Review?
Our north star is to use the best technology for every case, without bias for one approach over another. We’re convinced that generative AI is the best solution for many reviews, but we’re equally as ready to deploy active learning and hybrid workflows for other cases. As I mentioned earlier, we’ve seen a surprising surge in active learning utilization since aiR hit the scene, and we’re really excited about that too.
In terms of how we decide which to use, there are several factors such as whether we’re responding or receiving, who we’re producing to, document count, technology costs, and disclosure requirements.
You’ve been an influential voice and have made great strides in educating the public on generative AI. Why did you start down that path? What has it been like transitioning from behind the scenes to the spotlight?
In the years leading up to the current AI renaissance, the term “AI” had been diluted. You couldn’t log into LinkedIn for more than 30 seconds without seeing it a dozen times. We were drowning in it—yet, where was it? AI absolutely had an era of “emperor with no clothes.” But, alas, in a twist of fate, it was like the emperor willed his new clothes into existence.

LLMs weren’t new, but for the first time, they were widely available as API endpoints for developers. They spread like wildfire and permeated products across industries. On social media, there was no shortage of opinions and scenarioizing (all of which is good)—but I felt like there was a void of real information in the form of “look, we tested product X in scenarios A, B, and C, and here’s how it performed.”
So, when we got access to aiR, it felt right to go public and share what we were learning in real time. That’s what I’ve tried to do on LinkedIn and in articles over the last year. The industry response has been quite humbling. I hope to continue doing what I can to educate the community so they can choose the best technology and workflows for their cases.
What do you think will be the most impactful use cases of AI in e-discovery?
My first answer is going to be obvious: document review. Hopefully readers are familiar with aiR at this point, which is really the industry monolith for generative-AI-based document review in RelativityOne. When thinking about generative AI for document review, consider that, unlike using AI to draft documents or answer questions, we’re not asking the LLM to generate text. We’re only asking it to decide if a body of text (document) meets a set of conditions (our prompt). It performs exceedingly well at that task, where it isn’t susceptible to blunders like inventing case law or citations. More importantly, unlike a chatbot, document review (classification) results can be statistically validated—we can measure how well it works. That’s more difficult with a chatbot.
That said, the other use case that I think holds serious promise is the chatbot, particularly for fact-finding and investigations. Picture receiving a 20,000-document, incremental production and being able to ask: Did any employees of ABC Corp demonstrate awareness of a security vulnerability prior to the breach? Who was involved in approving postponement of the patching schedule? After the breach, what steps were taken to limit the exposure of private information?
In each case, the system returns a written answer in the form of, “Yes, John Doe and Sarah Jones exchanged emails in December of 2023 discussing anomalies logged by Newco’s cybersecurity team. They further identified the vulnerability on an outdated webserver.” Most chatbots would then also supply a list of documents and citations to support their answer.
The challenge with the chatbot is that answering these types of questions requires context from multiple documents, but only a limited number of documents fit into the context window of an LLM. Imagine you’re taking a test, and you’re only able to use the knowledge from 10 pages out of the textbook. There’s a lot of pressure on guessing the correct 10 pages to use. This is referred to as the “retrieval” stage in how a chatbot works. If the wrong 10 pages are retrieved, or there are more than 10 pages needed to answer the question, you’ll likely get the wrong answer.
So, they’re immensely powerful but also risky. I do see this as a temporary problem, though, as context windows are getting larger and may eventually become a non-factor. In the short run, how well a chatbot can address this problem will be the key to their success or failure.
What impact do you see generative AI technology like aiR for Review having on the legal field?
The ABA estimates that document review accounts for over 80 percent of total litigation spend, or $42.1 billion dollars a year. Consider that in combination with the fact over 90 percent of litigants say that document review costs have influenced the outcome of a case (e.g. caused settlement or impacted the amount). That’s a big deal when you consider the fidelity of the justice system at large. It means that case outcomes are, in many instances, determined or influenced by the cost to litigate rather than the merits (or lack thereof) of the claims. Sometimes in a big way. If we can slash review costs by, say, 75 percent, hopefully we can not only save our clients money, but also improve legal outcomes more generally.
In the same vein, consider the real-world impact of higher recall. If we can improve recall by 10-15 percent, without losing precision, that’s 10-15 percent more responsive/relevant documents exchanged between parties, which results in more facts and, again, higher-fidelity legal outcomes.
Put simply, to the extent that we can make document review cheaper and improve the discovery process, we’re improving the justice system’s ability to deliver just legal outcomes—and increasing access to justice.

You are our 2024 winner of the Relativity Innovation Award for AI. What was it like to receive your trophy on stage at Relativity Fest Chicago?
It was a major honor, and wouldn’t have happened without the significant contributions of Rachel Koy and Jonathan Moody. I also want to extend a big thank you to Scott Lombard, Jennifer Keough, Neil Zola, and David Isaac for trusting us to explore AI, and Kevin Marquis, who selflessly absorbed much of my case work so that I could focus on AI.

It’s so uplifting to feel the warmth and appreciation of the entire Relativity community. For those reading my articles, I hope you feel like they make “thought leadership” seem inviting, and less of an exclusive club. Everyone has a unique story and perspective, and I hope my plain language and practical advice spurs the thought: “hey, I could do that.”
Any parting words you’d like to leave us with?
Thank you, Relativity, Relativians, and the broader e-discovery community!
For 90 percent of industries, generative AI will improve efficiency by 10 percent. For 10 percent of industries, generative AI will improve efficiency by 90 percent. Without question, I think we’ll find e-discovery is in the latter.








