


In a blog post from early last year, e-discovery expert Ralph Losey said, “anyone can find relevant documents; find me key evidence.”
Differentiating between relevant and hot documents is an integral part of the review process. As we were building Relativity 7.5, we knew we wanted to help clients streamline their issue coding with Relativity Assisted Review. As is always the case with Assisted Review, the ability to discern between potentially responsive documents and key documents would require a combination of technology, process, and reporting.
First, we had to approach the technology. The categorization engine returns documents based on examples submitted by human reviewers. The results are based on conceptual similarity to the examples, and the engine provides a score for each document—for instance, a score of 95 out of 100 indicates a document is very similar to the original examples. To determine importance, we needed an intersection between that similarity score and a ranking based on the substantive issues categorized for the document. That way, we could see which documents are both responsive and rooted in key issues.
 Looking to the customized workflows of our clients, we realized that many experienced Relativity administrators were already leveraging categorization to organize documents by issue for batching and review. Inspired by their solutions, our team was determined to add a feature to Assisted Review that would help end users and administrators code for key issues. As a result, Assisted Review in Relativity 7.5 can run issue categorization in tandem with categorization for responsiveness. During the build, we also explored how reviewers would interact with the workflow. Should users select multiple issues for each document, or should they be focusing on one?
Looking to the customized workflows of our clients, we realized that many experienced Relativity administrators were already leveraging categorization to organize documents by issue for batching and review. Inspired by their solutions, our team was determined to add a feature to Assisted Review that would help end users and administrators code for key issues. As a result, Assisted Review in Relativity 7.5 can run issue categorization in tandem with categorization for responsiveness. During the build, we also explored how reviewers would interact with the workflow. Should users select multiple issues for each document, or should they be focusing on one?
Because the engine can only work with information provided to it, selecting multiple issues without providing the context around which string of text was related to each issue can mislead the computer on the true substance of those issues. To lessen that risk, we only allow reviewers to select the most representative issue for each document. This gives the engine the best opportunity to learn how each issue is manifested in relevant text, yielding more precise categorization results.
After reviewers select one issue per document and, in doing so, better define the depth of those issues, the computer is free to categorize up to five issues for each document. That automated ability to identify and assign multiple issues to a document is a big part of separating groups of responsive documents in a collection.
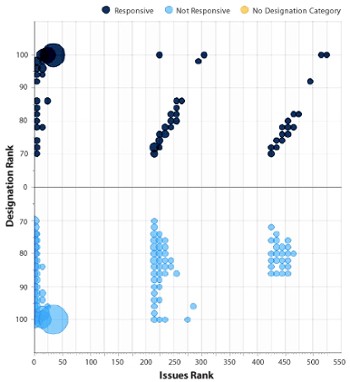
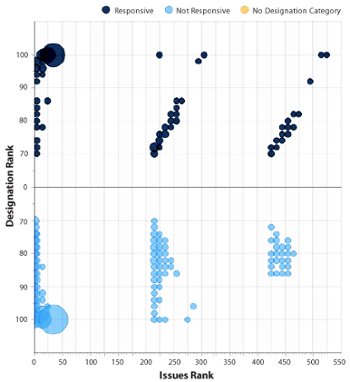
Now, we needed to help users understand the categorization results and find tangible takeaways related to the importance of each document. In addition to detailed, automated overturn and summary reports, we needed a solution that could report on the relationship between the responsiveness score and the key issues score. With that in mind, we identified a reporting metaphor to convey the importance of documents in Assisted Review—the bubble chart.
Using a relationship-based visual spread that resembles a scatter plot, bubble charts display three dimensions of data. Entities—represented as spheres—are plotted on the chart’s axes according to two variables, and sized according to the third variable.
Based on this metaphor, the designation-issue comparison report—which includes our bubble chart—was born. By defining the vertical axis based on designation and the horizontal axis based on issue rank, the report shows the intersection between potentially responsive documents and potentially key evidence. The size of the bubbles reflects the number of documents that fall in each intersection on the graph. In addition, the report highlights potential conflicts—for example, documents categorized as potentially non-responsive, but also assigned issues. The report can also provide insight into documents that are borderline responsive, and identify standout documents that are both highly responsive and highly relevant to a key issue—exactly what we were looking for at the beginning.
In the end, users get a comprehensive, multi-faceted view of their data. We’re excited about the ways this report can help make our users’ lives easier, and we’re interested in hearing about how folks are using the new report. Please feel free to contact us with your questions and feedback as you explore.






