



Just as with the technology-assisted review (TAR) methods that came in the two decades before its release, two fundamental questions remain at the heart of any conversation about whether generative AI is a viable option for document review for production or other targeted document requests:
- First, is it accurate?
- And second, is it defensible?
When TAR first became available, the defensibility of its use in litigation was rigorously scrutinized and debated. But a series of judicial decisions established it firmly, thanks in large part to the validation metrics that practitioners used to measure the accuracy of its results.
These statistical metrics included:
- Recall: the percentage of all relevant documents in a population that the AI correctly predicted to be relevant. A higher value is better.
- Precision: the percentage of documents in a population that the tool predicted are relevant, that are truly relevant. A higher value is better.
- Elusion: the percentage of documents predicted to be not relevant, that are actually relevant. A lower value is better.
- Richness: the percentage of all documents in the collection that are relevant. Higher or lower values aren’t better or worse, but a lower value often requires larger sample sizes for validation testing and may result in a wider margin for error.
Drawing on these strong foundations of validation, the same metrics can be calculated for generative AI results in document review to estimate the accuracy, reliability, and effectiveness of an AI model—and that calculation is easier to do than you might think.
While leaning on industry-standard validation can supply your confidence in the technology, the real contribution of generative AI to the topic of validation is when it happens. Generative AI enables legal professionals to validate performance before running a full review, allowing you to run statistically validated prompts from smaller document sets with the input of subject matter experts and senior reviewers across larger sets of documents. When we apply this concept to Relativity aiR for Review, the workflow looks like this:
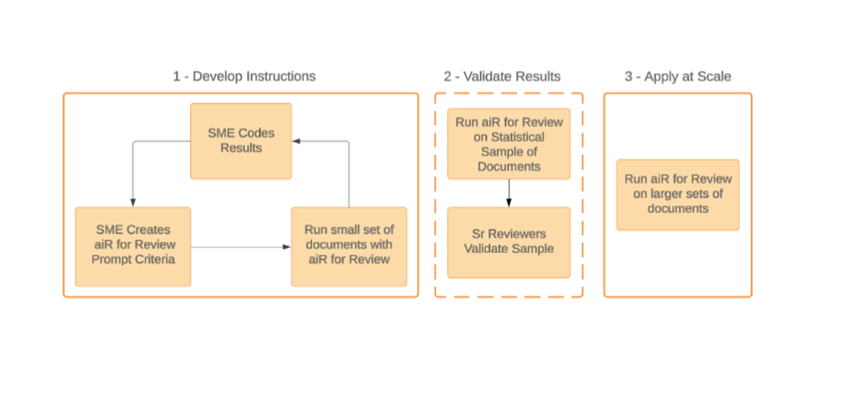
By refining prompt criteria early, lawyers can assess recall, precision, and elusion upfront, ensuring aiR for Review is optimized before large-scale application.
“Being able to assess recall and precision before committing to a full review run is a major advantage. If the results meet expectations, we can proceed with confidence. If they fall short, we can return to iteration, revise the prompt, and re-validate, improving the results without the cost of a full-scale do-over. From a disclosure standpoint, early validation also allows the producing party to set expectations about how well the process will perform. And if negotiations falter, the team can modify their review plan with little wasted effort."
Ben Sexton, Senior Vice President, Innovation & strategy, JND eDiscovery
Don’t Just Trust, Verify: Evaluating the Accuracy of Generative AI for Doc Review
Evaluating the output of your generative AI document review projects via these methods will help you build confidence within your team and stakeholders, ensure that proper human oversight guides AI workflows at all times, and help prevent costly rework downstream.
Minimize Repetitive Work and Redos
Some common advice from seasoned experts in generative AI is to “start small.” You can avoid rework and evaluate the efficacy of your prompt criteria before it’s used at scale by running validation exercises on small sets of data first.
Unlike TAR 1.0 and 2.0 workflows, generative AI provides the ability to proactively validate up front, creating efficiencies throughout the entire workflow. By testing your prompt criteria against a small subset of data, measuring the AI’s performance, and tweaking your prompt criteria accordingly, you can avoid missing critical material or overproducing documents when you run it on the full document population.
Ensure Consistent Performance to Build Tech Trust
Statistical validation helps you establish trust in your process among clients and stakeholders by gathering quantitative evidence that the results of your AI workflows are consistent.
Alongside careful analysis of AI’s rationales and citations, which offer a qualitative method of evaluating its outputs and minimizing the “black box” perception of AI and how it makes decisions during a document review, statistical validation is an important quantitative way to verify the accuracy of those decisions.
Balance Human and Artificial Intelligence
Artificial intelligence is most performant and most beneficial when it works in sync with human intelligence. Especially when you face particularly complex review projects, statistical validation can help you pinpoint where AI’s predictions diverge from those of your SMEs. Digging into that insight early in the process can help you make meaningful adjustments to your prompt criteria and get the results you need.
How Do You Validate Relativity aiR for Review’s Results?
A recent white paper from Relativity walks through the built-in ways aiR for Review users can validate the output of the AI model, objectively measuring the accuracy of its results with industry-accepted statistical principles that mirror those established for previous TAR workflows.
A framework for measuring these values is built into aiR for Review and RelativityOne’s Review Center, enabling users to objectively evaluate aiR’s accuracy. This statistical validation should become a crucial step in your generative AI workflows—whether you’re preparing to defend them to opposing counsel or simply pausing to evaluate the effectiveness of your prompt criteria before running it on a larger set of documents.
For more detailed information, please download our free white paper: “Defensible Validation of Relativity aiR for Review: Metrics, Methods, and Considerations.” There, you’ll find all the details you need on why these metrics matter, what they mean, and how to calculate them for your projects.
Questions? We’re here to help! Get in touch with us via your customer success manager, account manager, or by reaching out here for assistance.
Graphics for this article were created by Caroline Patterson.








